Using IA and Glacier for a S3 logs bucket
This article aims to talk about some points that must be taken into account when designing lifecycle rules for a bucket whose contents are logs. Note: The same logic can be applied for any buckets that are mostly/only composed of small objects (less than 128kb).
Let's look at the following lifecycle policy:
Type: 'AWS::S3::Bucket'
Properties:
AccessControl: Private
LifecycleConfiguration:
Rules:
Status: 'Enabled'
Transitions:
- TransitionInDays: 30
StorageClass: STANDARD_IA
- TransitionInDays: 180
StorageClass: GLACIER
Theoretically, it makes sense that to reduce costs storage, which normally will not be consulted frequently, move logs objects to the STANDARD_IA class after 30 days of their creation and to GLACIER after 180 days.
From S3 standard to Infrequent Access Standard
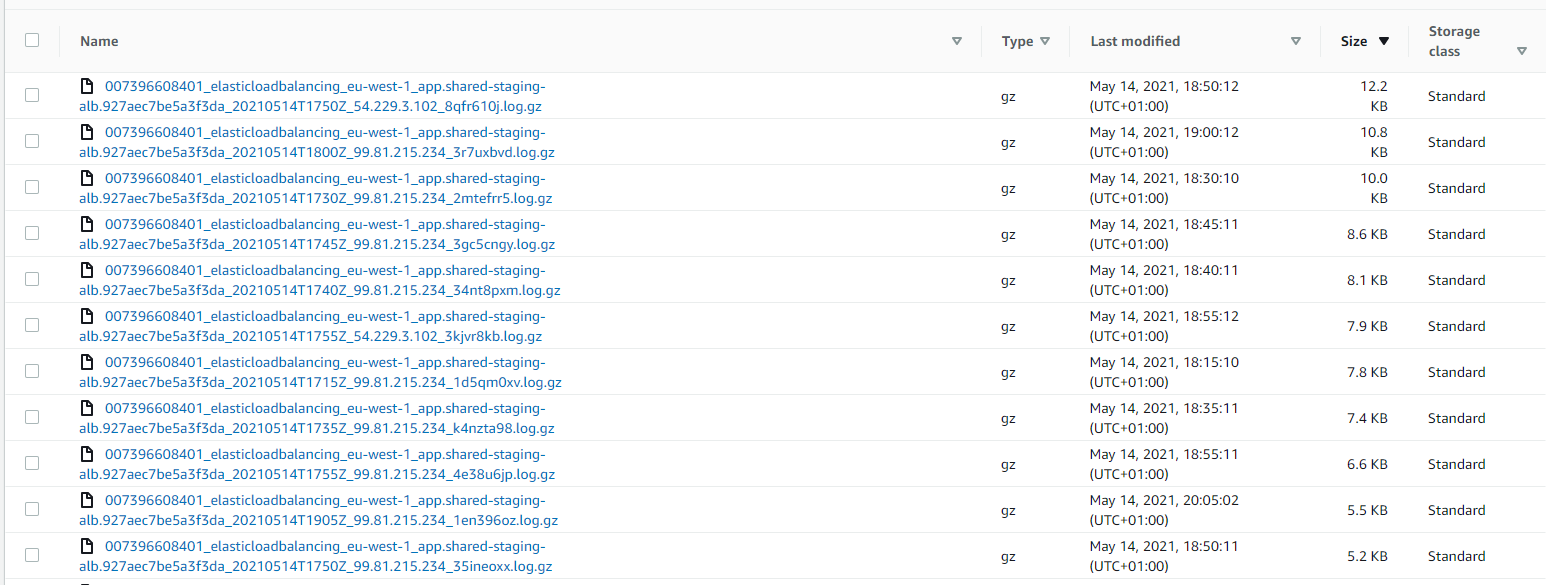
Assuming that logs by nature form objects of only a few kb (see image) it will not be possible to create a lifecycle rule. According to the documentation "for the following transitions, Amazon S3 does not transition objects that are smaller than 128 KB because it's not cost effective". It is also not advisable to manually pass these objects to AI as regardless of their actual size, each object will be considered to have a size of 128kb ( see here) .
From S3 standard to Glacier
Passing to Glacier might not be a good idea. The problem here concerns the metadata that has to be associated with an object that happens to be in the GLACIER class.
According to the documentation , each object that passes to glacier has an associated 40kb of meta (8kb for the name and 32kb for the index).
So for a case where 25000 objects are generated per month about 1 Gb of metadata would be stored (storage cost per GB is around 0.004 euro per GB/month)
Conclusion
In this way, it is important, before establishing a lifecycle rule, to take into account the implications of each passage. It can be concluded that for buckets with many and small objects such a policy may not have many benefits.