Trying Bitbucket Pipelines' Parallel Steps


The purpose of this article is to registered a prove of concept regarding the use of parallel steps . In short, this tool allows you to divide a single step into several steps that will run simultaneously. Allowing a faster execution.
As testing scenario I used parallel steps in the execution of the test step (rspec) of a generic ruby on rails application.
The biggest challenge relied on finding a way to measure the total coverage. For measuring coverage I used SimpleCov. Running parallel steps block the possibility to have the registration of total coverage since SimpleCov records the coverage of the last rspec command that was executed, regardless of whether it was from a single folder or the entire test suite.
The solution found for this problem involved the use of artifacts . Artifact is a mechanism used to allow files to be accessed in later steps. This is necessary because each pipeline step spins a new container (which does not know what was generated in previous steps/containers).
In practical terms, each step that runs a test semi-suite generates a .last_run.json file, which shows, in total percentage, the coverage of that sub-suite. In order to calculate the total coverage I would need to access the collection of all .last_run.json originated in all parallel steps.
The solution was to rename each of these files, so that they were not overwritten. For this I used the variable $BITBUCKET_PARALLEL_STEP that is accessible to any of the steps that run in parallel and that represents the current step in the group:
cp coverage/.last_run.json coverage/report_$(( $BITBUCKET_PARALLEL_STEP + 1 )).json
I also used the variable $BITBUCKET_PARALLEL_STEP_COUNT, which allowed me to access the total number of steps in the group. As this variable is only accessible in the steps that run in parallel and our intention was to use it after those, I created a .txt where I put it in.
echo $BITBUCKET_PARALLEL_STEP_COUNT >> coverage/iterations.txt
Then, this file is passed on as an artifact to be accessible in later steps:
artifacts:
- coverage/report_*.json
- coverage/iterations.txt
After running all the parallel steps, I created a step called coverage whose goal was to read the various report*.json files and add all the percentages in order to obtain the total coverage of the application.
I used iterations.txt in order to know how many times I have to iterate through the folder, in order to collect all files.
Script used:
#/bin/bash
ITERATIONS=$(cat coverage/iterations.txt)
COVERAGE=0
for i in $(seq 1 $ITERATIONS)
do
CURRENT=$(cat coverage/report_${i}.json | jq 'if .result.covered_percent then
.result.covered_percent else .result.line end')
echo "current ${CURRENT}"
COVERAGE=$(echo "$COVERAGE + $CURRENT" | bc)
done
if [[ $(echo "$COVERAGE < 50" | bc) == 1 ]]; then
echo "SHAME! Test coverage is too low to proceed... $COVERAGE%...really?"
exit 1
fi
echo "Congrats! your are contributing to a better world by having $COVERAGE% of your code covered by tests!"
exit 0
Bitbucket-pipelines.yml:
image:
name: <your-pipelines-image>
(...)
steps:
(...)
- parallel: &test
- step:
name: Model Specs
script:
- bundle install
- bundle exec rspec spec/models
- cp coverage/.last_run.json coverage/report_$(( $BITBUCKET_PARALLEL_STEP + 1 )).json
- echo $BITBUCKET_PARALLEL_STEP_COUNT >> coverage/iterations.txt <-- only once
services:
- mysql
artifacts:
- coverage/report_*.json
- coverage/iterations.txt
- step:
name: Jobs Specs
script:
- bundle install
- bundle exec rspec spec/jobs
- cp coverage/.last_run.json coverage/report_$(( $BITBUCKET_PARALLEL_STEP + 1 )).json
services:
- mysql
artifacts:
- coverage/report_*.json
- step:
name: Policies Specs
script:
- bundle install
- bundle exec rspec spec/policies
- cp coverage/.last_run.json coverage/report_$(( $BITBUCKET_PARALLEL_STEP + 1 )).json
services:
- mysql
artifacts:
- coverage/report_*.json
- step:
name: Requests Specs
script:
- bundle install
- bundle exec rspec spec/requests
- cp coverage/.last_run.json coverage/report_$(( $BITBUCKET_PARALLEL_STEP + 1 )).json
services:
- mysql
artifacts:
- coverage/report_*.json
pipelines:
branches:
test/test-pipeline:
- parallel: *test
- step: *coverage
Conclusions: After implementation, I preceded a benchmark in order to know if the solution would make sense in my app's context.
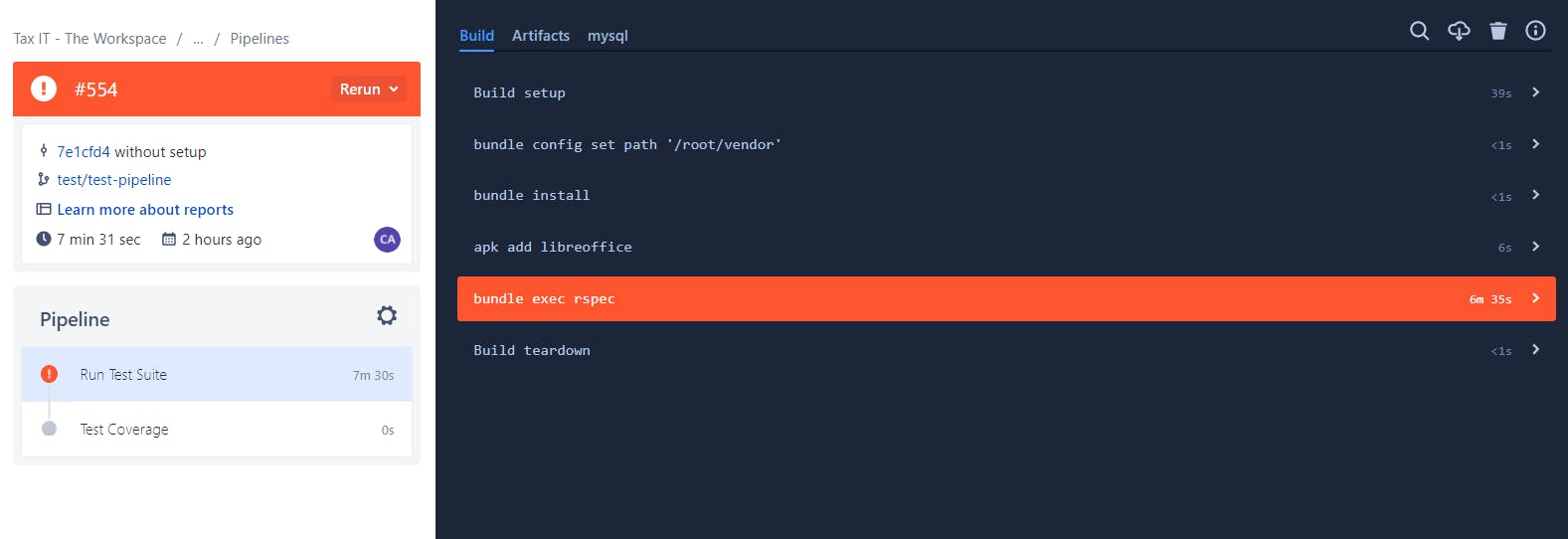
Without parallelism:
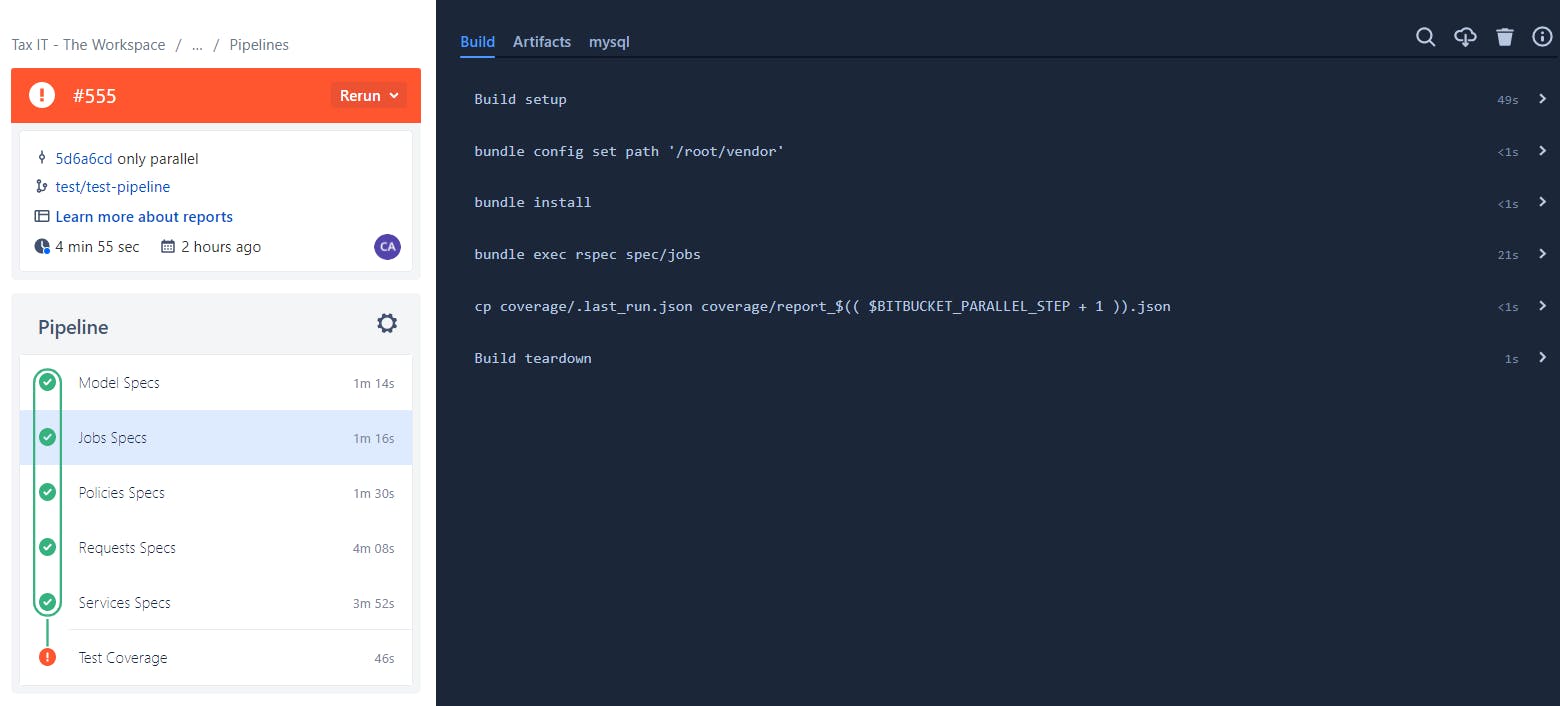
With parallelism:
Main points:
The parallelism made it possible to run the test step faster (4m 55s vs 7m 31s).
Since the paid minutes do not correspond to 4: 55s but the sum of the minutes of all parallel steps (~11m), the minutes paid in parallelism was higher than the minutes paid without parallelism.
There seems to be a minimum of 1 minute per step, in parallel steps, which makes the solution optimal only for situations in which the efficiency gain outweighs the loss by the minimum cost per step that there seems to be.
This does not seem to be our case since most of our applications run the test suite in a short time.